Attend What Matters: Leveraging Vision Foundational Models for Breast Cancer Classification Using Mammograms
Abstract
Vision Transformers (ViTs) have become the architecture of choice for many computer vision tasks, yet their performance in computer-aided diagnostics remains limited. Focusing on breast cancer detection from mammograms (BCDM), we identify two main causes for this shortfall. First, medical images are high-resolution with small abnormalities, leading to an excessive number of tokens and making it difficult for the softmax-based attention to localize and attend to relevant regions. Second, medical image classification is inherently fine-grained, with low inter-class and high intra-class variability, where standard cross-entropy training is insufficient. To overcome these challenges, we propose a framework with three key components: (1) Region of interest (RoI) based token reduction using an object detection model to guide attention; (2) contrastive learning between selected RoIs to enhance fine-grained discrimination through hard-negative based training; and (3) a DINOv2 pretrained ViT that captures localization-aware, fine-grained features instead of global CLIP representations. Experiments on public mammography datasets demonstrate that our method achieves superior performance over existing baselines, establishing its effectiveness and potential clinical utility for large-scale breast cancer screening.
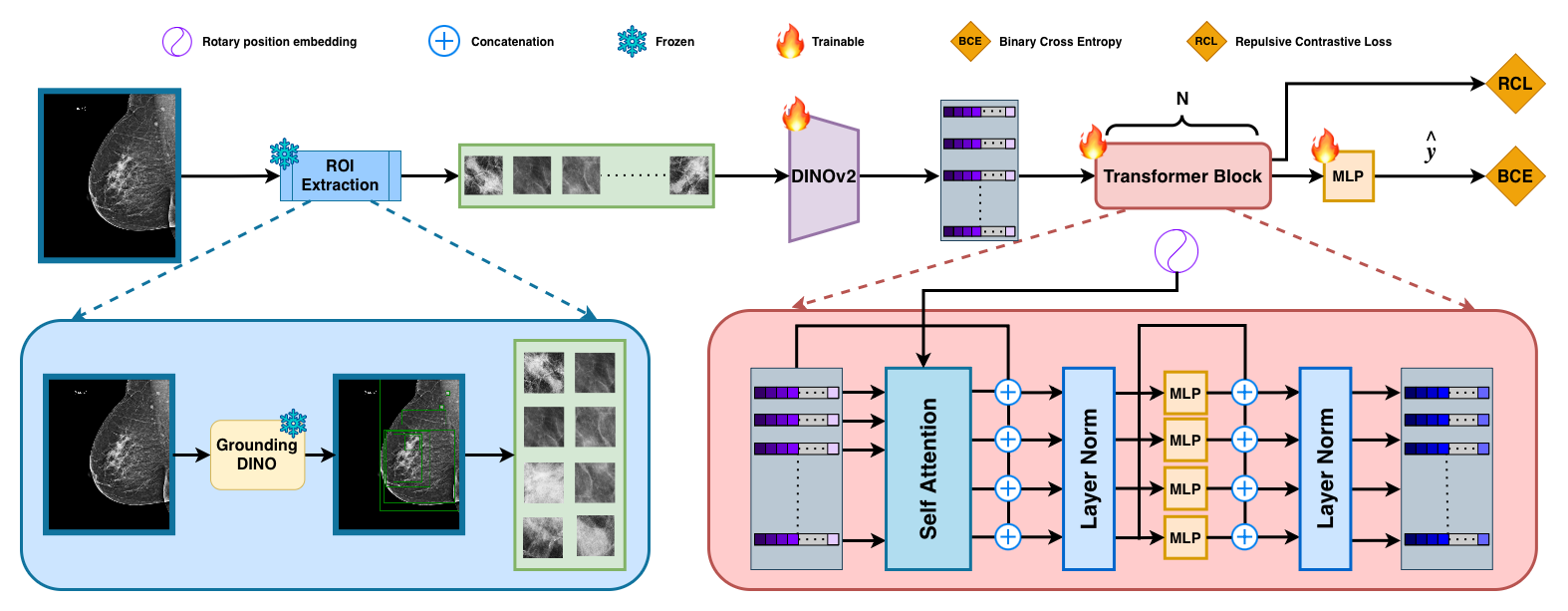
Figure 1: Overview of the Attend What Matters framework.
Results
| Method | AUC | F1 | R@0.1 | R@0.3 | R@0.5 |
|---|---|---|---|---|---|
| Vision only | |||||
| ViT-A | 79.0 | 41.1 | 55.0 | 71.2 | 84.3 |
| ViT-B | 83.0 | 50.0 | 61.4 | 77.0 | 86.9 |
| ViT-C | 78.4 | 31.1 | 43.7 | 67.2 | 82.4 |
| MedVAE | 57.5 | 20.6 | 23.7 | 41.9 | 60.1 |
| TReg-SwinT | 85.8 | 53.0 | 55.1 | 80.6 | 90.2 |
| XFMamba | 63.6 | 18.3 | 25.2 | 51.5 | 64.6 |
| Image-Text | |||||
| MMBCD | 77.1 | 27 | 50 | 66.2 | 82.8 |
| M-C-B5 | 85.8 | 50.8 | 65.4 | 83.5 | 89.9 |
| Ours | 86.6 | 54.5 | 66.5 | 80.7 | 90.3 |
Table 1: Performance comparison on the VinDR dataset. ViT-A and ViT-B correspond to DINO with a linear layer at input resolutions of 448x448 and 1024x1024 respectively. ViT-C demonstrates scores using a DeIT head instead of a linear layer at 448x448 input resolution.
Citation
@inproceedings{sanghvi2026attend,
title={Attend What Matters: Leveraging Vision Foundational Models for Breast Cancer Classification Using Mammograms},
author={Sanghvi, Samyak and Miglani, Piyush and Shashikumar, Sarvesh and Borgavi, Kaustubh R and Singla, Veenu and Arora, Chetan},
booktitle={IEEE International Symposium on Biomedical Imaging (ISBI)},
year={2026}
}